
This post covers my current thinking on what I consider the optimal way to work with R on the Google Cloud Platform (GCP). It seems this has developed into my niche, and I get questions about it so would like to be able to point to a URL.
Both R and the GCP rapidly evolve, so this will have to be updated I guess at some point in the future, but even as things stand now you can do some wonderful things with R, and can multiply those out to potentially billions of users with GCP. The only limit is ambition.
The common scenarios I want to cover are:
- Scaling a standalone R script
- Scaling Shiny apps and R APIs
It always starts with Docker
Docker is the main mechanism to achieve scale on GCP.
It encapsulates code into a unit of computation that can be built on top of, one which doesn’t care which language or system that code needs to run.
This means that a lot of the techniques described are not specific to R - you could have components running Python, Java, Rust, Node, whatever is easiest for you. I do think that Docker’s strengths seems to cover R’s weaknesses particularly well, but having Docker skills is going to be useful whatever you are doing, and is a good investment in the future.
There is growing support for Docker in R, of which I’ll mention:
- The Rocker Project is where it all flows from, providing useful R Docker images
- containerit is helpful to quickly generate a Dockerfile from an R script or project
- steveadore is a Docker client written in R
Within GCP containers are fundamental and once you have a Docker image, you will be able to use many of GCP’s services both now and in the future, as well as on other cloud providers. The tools I use day to day with my Docker workflows are:
- Build Triggers - I never build Docker on my machine, I always commit the Dockerfiles to GitHub and then this service builds them for me.
- Container registry - Once built images are available from here. They are by default private, and over time I’ve built a library of useful images. Some of these are available publically at this repo (you do need to login though)
The above are used within googleComputeEngineR’s templates, so as RStudio, Shiny and R APIs can be launched quickly.
This basically constitutes a continuous delivery (CD) basis, so to deploy new code I need but push to GitHub and my script, Shiny app, R API or model are updated automatically.
1. Scaling an R script
The first scenario is where you have a script that does something cool, but now you need it to say run against more data than you can throw at it locally or don’t have the CPU resources. In that case you can choose to scale either horizontally or vertically.
1A - Vertical scaling aka “Getting a bigger boat”

Vertical scaling is where you just throw more power at the problem. As R is RAM based, then often the easiest solution is to just run the script on a machine with massive RAM.
Pros
- probably run the same code with no changes needed
- easy to setup
Cons
- expensive
- may be better to have data in database
And it can be massive. Google Compute Engine offers instances with up to 3.75TB of RAM which can probably eat most jobs. To do so, change the machine type to say n1-ultramem-160 that gives you 160 CPU cores as well. (The ultra-mem machine type)
Launching this with googleComputeEngineR:
library(googleComputeEngineR)
# this will cost a lot
bigmem <- gce_vm("big-mem", template = "rstudio", predefined_type = "n1-ultramem-160")
It will cost you $423 a day, so be ready before you launch such a beast.
Dealing with data size
However, it is rare that data is in a format that would directly benefit from this much RAM.
Just reading the data will take time at this volumes, and should not be done via CSV files.
Better alternatives include Apache arrow, library(feather) or data.table().
And if your data is that size, why isn’t it in a database? For most analytics tasks like that I reach for BigQuery, which then follows that perhaps you don’t need so much RAM if your code is batching operations on the data. For that you can use bigrquery or bigQueryR.
1B - Horizontal scaling aka “The Dunkirk”

Pros
- Docker image created that is available for other workflows
- library(future) interface lets same code work with different scaling strategies like multisession, multicore or multi-instance.
Cons
- probably have to change your code so it can be done via split-map-reduce
- have to write meta code to handle the interface of data and code
- Not applicable to some problems that need to calculate on all data at once.
This is actually the more common path for me, and its here where Docker starts to come into play. The idea here is to split up your task into bite sized pieces, run your script on those bits then merge them all back together again, or a split-map-reduce workflow. Not all data problems can be tackled this way, but I would say most can be.
What appeals most to me here is that each time you build the blocks for a job, you may not have to start from scratch - for instance I often reuse images that say connect to BigQuery, and swap the script over.
To achieve this has become a lot easier in R with the future package, which standardises multicore processing in R, and enables one to take your code and work it on many cores or instances in the cloud. Again, you may find this easier to do on one big VM with lots of cores, or many small VMs. The code is similar in both cases, but the setup is not, and make sure to include code to tear down the instances again afterwards.
I have a few examples on the googleComputeEngineR website as its a popular application. A full example from there is shown below:
library(future)
library(googleComputeEngineR)
## names for your cluster - just three for this example
vm_names <- c("vm1","vm2","vm3")
my_docker <- gce_tag_container("custom-image", project = "my-project")
## create the cluster using custom docker image
## creates jobs that are creating VMs in background
jobs <- lapply(vm_names, function(x) {
gce_vm_template(template = "r-base",
predefined_type = "n1-highmem-2",
name = x,
dynamic_image = my_docker,
wait = FALSE)
})
## wait for all the jobs to complete and VMs are ready
vms <- lapply(vm_names, gce_wait)
## set up SSH for the VMs
vms <- lapply(vms, gce_ssh_setup) # set any settings necessary here for SSH
## the Rscript command that will run in the cluster
## customise as needed, this for example sets shared RAM to 13GB
my_rscript <- c("docker",
"run", c("--net=host","--shm-size=13G"),
docker_image,
"Rscript")
## create the future cluster
plan(cluster,
workers = as.cluster(vms,
docker_image=my_docker,
rscript=my_rscript),
## create the list of data to run on the cluster
## here we assume they are in a folder of CSVs
## and there are as many files as VMs to run it upon
my_files <- list.files("myfolder")
my_data <- lapply(my_files, read.csv)
## make an expensive function to run asynchronously
cluster_f <- function(my_data, args = 4){
forecast::forecast(forecast::auto.arima(ts(my_data, frequency = args)))
}
## send to cluster
result <- future::future_lapply(my_data, cluster_f, args = 4)
## once done this will be TRUE
resolved(result)
## Your list of forecasts are now available
result
1C - Horizontal Kubernetes - aka “Jason and the Argonauts”

Pros
- takes advantage of Kubernetes features such as auto-scaling, task queues etc.
- potentially cheaper
Cons
- need to create stateless, idempotent workflows
- need to make some kind of message broker that decides which bits of data to work on for each pod.
Once you are dealing with clusters of machines and Dockerfiles, the natural next step is Kubernetes.
This is not (yet) facilitated using library(future) so is a bit more difficult to setup if you want to roll your own. I think that in time an R specific platform will evolve that will take advantage of the main benefits such as auto-scaling and preemptive image management, which will be much cheaper in the long run if you need to do this kind of operation many times. RStudio Server Pro is already offering this via its Job Launcher.
If you are looking to roll your own, the most popular post on this blog at the moment is the R on Kubernetes walk-through of my setup.
As the pods of Kubernetes are usually stateless (I don’t know how to do a stateful cluster) then you need to make sure the data bits that each pod operates on is able to work completely separately, and also coordinate which bits have been worked on and which should be used for future. Tamas has a guide on how to set up parallelizing R code on Kubernetes which is well worth the read.
2. Scaling R applications
Now I turn to cloud applications of R - you have written your code and want to activate that analysis by providing its results, either in a Shiny interactive visualisation or via an API others can call to get the results.
First - Dockerise your app
The first step is to copy your app folder into a Docker container with all the R libraries you need installed. From there you are ready to take advantage of almost any cloud providers services.
The Dockerfiles are relatively simple, thanks to rocker/shiny:
FROM rocker/shiny
MAINTAINER Mark Edmondson (r@sunholo.com)
# install R package dependencies
RUN apt-get update && apt-get install -y \
libssl-dev \
## clean up
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/ \
&& rm -rf /tmp/downloaded_packages/ /tmp/*.rds
## Install packages from CRAN needed for your app
RUN install2.r --error \
-r 'http://cran.rstudio.com' \
googleAuthR \
&& Rscript -e "devtools::install_github(c('MarkEdmondson1234/googleAnalyticsR')" \
## clean up
&& rm -rf /tmp/downloaded_packages/ /tmp/*.rds
## assume shiny app is in build folder /shiny
COPY ./shiny/ /srv/shiny-server/myapp/
When deploying Shiny apps, the biggest stumbling block I have found is that Shiny requires websocket support. Check your solution first to see if it can deal with websockets before deployment. For instance, App Engine Flexible or Cloud Functions would be a better serverless solutions if websockets were supported, as it would give you a more managed service.
If deploying an R API via plumber, the Dockerfile is largely the same thanks to trestletech/plumber taking care of the defaults for you, including serving on port 8000.
Say we have the example plumber script saved to api.R:
#* Echo back the input
#* @param msg The message to echo
#* @get /api/echo
function(msg=""){
list(msg = paste0("The message is: '", msg, "'"))
}
Then the Dockerfile could look like:
FROM trestletech/plumber
# copy your plumbed R script
COPY api.R /api.R
# default is to run the plumbed script
CMD ["api.R"]
2A - Low traffic R apps
If you only have a few users and no existing resources, you could set up a VM that will handle the requests. In that situation you can just use the googleComputeEngineR template for Shiny:
library(googleComputeEngineR)
## make new Shiny template VM for your self-contained Shiny app
vm <- gce_vm("myapp",
template = "shiny",
predefined_type = "n1-standard-2",
dynamic_image = gce_tag_container("custom-shiny-app", "your-project"))
And if you do that, you still have a Docker image which can then easily be moved to other platforms when you are ready to scale.
I always want an API to scale so would suggest it is always deployed to a more flexible solution - autoscaling is the killer feature so you aren’t losing requests in high peaks or keeping around spare capacity when you are at traffic lows.
2A1 - R APIs on Cloud Run
this is updated from the original blog post in summer 2019
Now I’ve made a package to make R APIs easier to deploy onto Cloud Run - see googleCloudRunner for details!
Pros
- Scale to billions
- Keeps costs low
- easy to deploy
Cons
- Works with stateless apps only, so R APIs, and limited Shiny - see https://code.markedmondson.me/shiny-cloudrun
Now Google has released Cloud Run! And with that release, I modify my original recommendation for R APIs to be deployed on Kubernetes, to instead use Cloud Run.
Why? Its so simple. After you have made your Docker container for your plumber API, you simply point the Cloud run service at the image and you are done. Hosting, scaling and the rest is all taken care of.
To help demonstrate, I’ve made a GitHub report for CloudRunR that deploys the demo plumber app.
The only trick to it really is to allow Cloud Run to set the port plumber listens on, which is done via this Dockerfile:
FROM trestletech/plumber
LABEL maintainer="mark"
COPY [".", "./"]
ENTRYPOINT ["R", "-e", "pr <- plumber::plumb(commandArgs()[4]); pr$run(host='0.0.0.0', port=as.numeric(Sys.getenv('PORT')))"]
CMD ["api.R"]
Once the Cloud Build has finished it will give you a Docker URI such as gcr.io/mark-edmondson-gde/cloudrunr:939c04dfe80a1eefed28f9dd59aae5dff5dc1e1e.
- Go to https://console.cloud.google.com/run/
- Create a new service, name it something cool
- Put the Docker URI into the Cloud Run field.
- Select public endpoint, and limit concurrency to what your app is configured to handle per instance (I chose 8)
And thats it. A deployed R API.
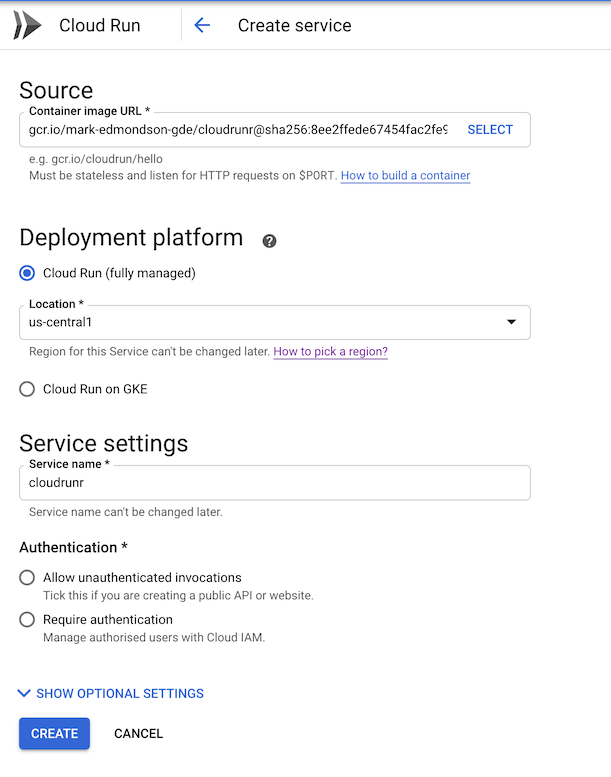
You will then get a URL for the API you can use. For this demo app the endpoints are /hello, /echo?msg=“my message” and /plot (or filter the plot via /plot?spec=setosa)
- https://cloudrunr-ewjogewawq-uc.a.run.app/hello
- https://cloudrunr-ewjogewawq-uc.a.run.app/echo?msg=my%20message
- https://cloudrunr-ewjogewawq-uc.a.run.app/plot
- https://cloudrunr-ewjogewawq-uc.a.run.app/plot?spec=setosa
But what about Shiny apps? Well this is a work in progress and some limited Shiny apps do also work on Cloud Run. See the blog post about running Shiny on Cloud Run
2B - R apps on Kubernetes
Pros
- Scale to billions
- Keeps costs low
Cons
- Minimum useage level required to be better than just deploying on a single VM.
Kubernetes will take care of deploying the right number of pods to scale your traffic, and starts to make savings once you are past 3 VMs. You may already have a kubernetes cluster deployed for other things at your company (its getting very popular with IT teams), in which case you can hitch onto an existing cluster.
Its mainly due to the need of websockets that I recommend going straight to Kubernetes once you have need for more than a couple of Shiny apps, rather than say App Engine flexible. I have an example of deploying plumber on App Engine flexible that you may favour, but these days since I have a kubernetes cluster already deployed for other things I find it easier to deploy it all on that.
Once setup, deployment is quick via the CLI:
kubectl run shiny1 --image gcr.io/gcer-public/shiny-googleauthrdemo:latest --port 3838
kubectl expose deployment shiny1 --target-port=3838 --type=NodePort
The trickest thing is the ingress, but once grokked works by uploading some boilerplate yaml:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: r-ingress-nginx
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/rewrite-target: /
nginx.ingress.kubernetes.io/ssl-redirect: "false"
spec:
rules:
- http:
paths:
- path: /gar/
# app deployed to /gar/shiny/
backend:
serviceName: shiny1
servicePort: 3838
Some more detail is in the Kubernetes blog post.
Summary
With the introduction of Cloud Run, the options get simpler for R APIs, although in all circumstances the first suggestion is “Use Docker!”. Cloud Run is a level of service built on top of Kubernetes, but if you can’t use that then “Use Kubernetes!” is the next byword for scale.
In all cases, having that Docker container gives you the flexibility to swap once the new services comes along. Cloud Functions and App Engine in particular are the next step in managed services, and perhaps in the future you won’t even need to create the Docker image - just upload your code, it builds the Dockerfile for you then deploys.