I’ve been working on googleCloudRunner over the last couple months which is soon available on CRAN - https://code.markedmondson.me/googleCloudRunner/
googleCloudRunner feels like the culmination of my last couple of years interest in this R/Google Cloud Platform niche I find myself in. The package seems to fulfill every use case I have wanted for working with R in the cloud, available now in a simple UI syntax that hopefully any R user can pick up quickly. Those use cases include:
- scheduling an R script
- creating an R API for R-as-a-Service
- data pipelines where R input/output can be integrated with non-R applications
- ’event driven’ R workloads, where R can be triggered e.g. pub/sub events, GitHub commits
These use cases and other practicalities are outlined on the googleCloudRunner website and use-case section, but for this blog post I’d like to talk about how the package evolved alongside my increased understanding of how the cloud differs from local development. This post will mirror a talk I will give at R v1.0.0’s 20th birthday party in Copenhagen this year on Feb 28th.
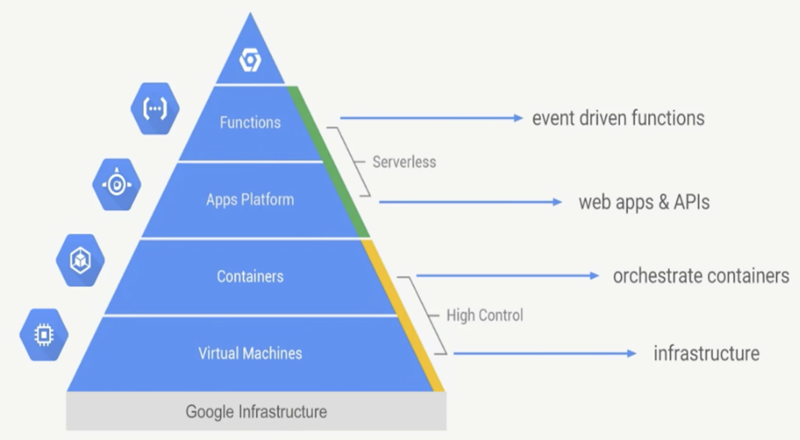
My journey up the Pyramid
My journey has been one of learning increasing levels of abstraction. Abstraction has been a motivation for me all the back to the start of my career in digital marketing in 2006, and has been key to my enjoying my work - how does what I’m doing now fit into a wider picture? The next step has not always been obvious, but when I look back I’ve always been drawn in that direction.
For example, my work roles have evolved over time from:
- Finding links for SEO purposes (start using Python)
- Applying SEO to websites
- Measuring SEO’s impact via Google Analytics
- Tracking all website visits via Google Analytics (start using JavaScript)
- Analysis of data extracted from Google Analytics (start using R)
- Automating data analysis via servers in the cloud (start using Docker)
- Scaling data pipelines within the cloud (start using SQL)
- Creating use cases for data pipelines
Digital marketing/cloud is a nice verticial to work in for this since there are lots of new things to try each month. As a market it evolves rapidly.
This abstraction has also happened with my understanding of R programming:
- R code - struggling through the R learning curve
- R functions - moving towards more reproducability and modularity
- R packages - bundling up useful functions into versioned packages
- Docker environments of R packages - fixing package versions and dependencies
- Running R environments on servers - scaling lots of R environments for parallel/reliability
- Running R environments on serverless services - abstracting dev-ops to cloud platforms
Google itself talks about abstraction of its infrastructure from the point of view of how much controlled vs managed solutions you want, and I have moved up that infrastucture as time has gone on, from its base with virtual machines to the peak submitting R functions for GCP to deal with.
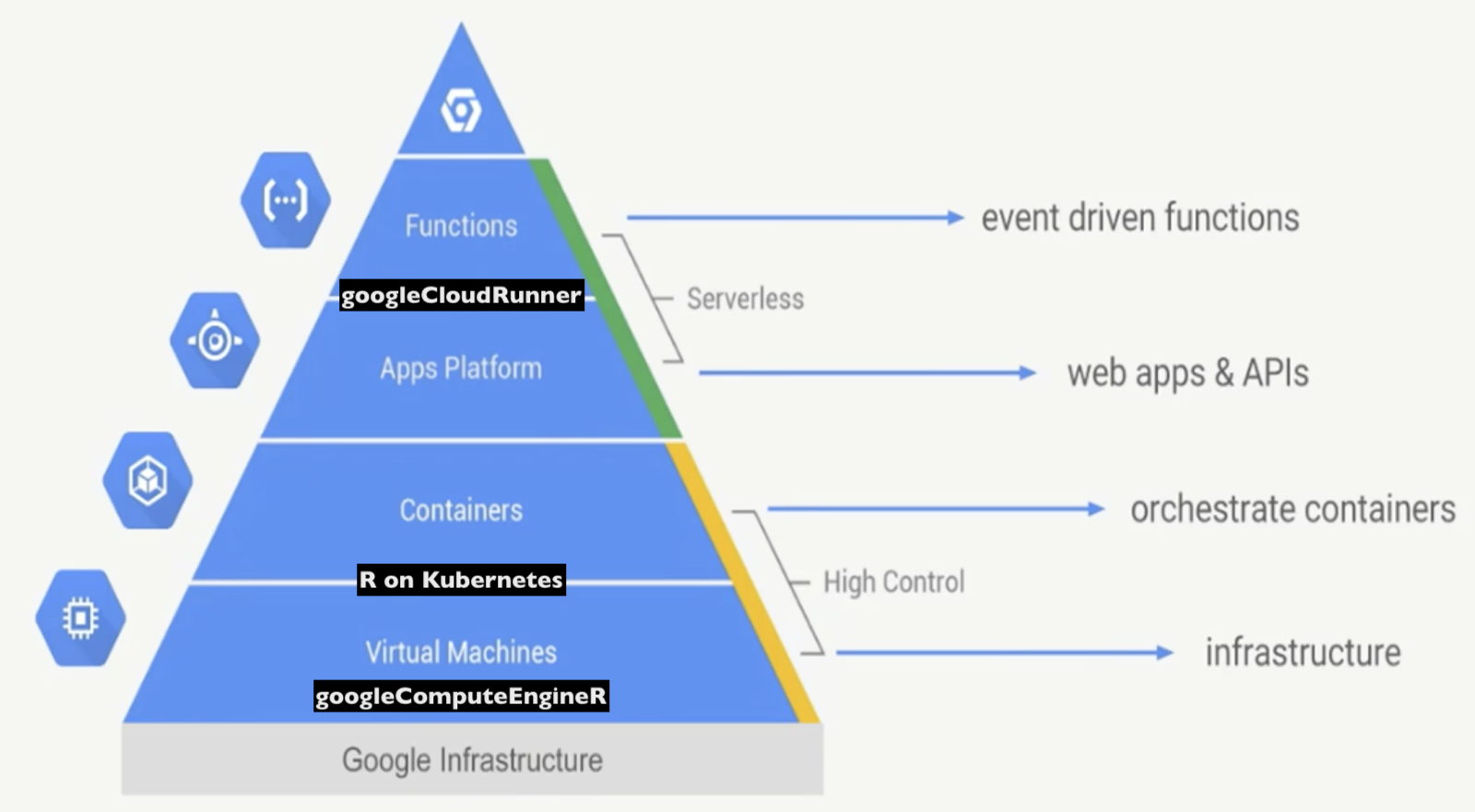
googleComputeEngineR published in 2017 created VMs (virtual machines) much like your own machine sitting at home. As I got used to configuring compute via code more advanced uses were found via utilising Docker containers to replicate R environments, such as massive parallel processing and firing up customised RStudio or Shiny servers.
Docker really is the key to how you move up the pyramid - it enables almost everything beyond base infrastructure and is my highest recommendation for learning if you are interested in following a similar track
The more meta-code I wrote to manage these services, the more standard they get and I realised that platforms offered a more robust way on top of those same VMs I was coordinating. The market leader for the management of Docker containers on multiple machines is Kubernetes, which this post talks about and tracks my journey deploying R through it in 2018.
But Kubernetes I have concluded is only really needed if you are building a platform. It lets you do hard things easily (auto-scaling multiple containers) but some easy things are more difficult (assigning a https outside ip address and authenticating it), so a more managed service on top of it is preferable if available for your needs.
Many platforms build on top of Kubernetes, including Knative. Knative takes care of details such as scale-to-zero, authentication etc. so you only need to worry about deploying containers with your code and everything else is taken care of. Google Cloud Platform’s managed Knative service is Cloud Run, which reached general availability recently and is now, via googleCloudRunner, my preferred service for R APIs.
You can read more about this via this presentation on R at scale on Google Cloud Platform I made in New York in September 2019
Along the way, a few key highlights of the lessons for moving into the cloud have been:
- separation of code, data and configuration
- events not schedules
- technical debt of code vs no-code
I would like to talk about how googleCloudRunner manifests these learnings in its approach.
Separation of Code, Data and Configuration

Being able to decouple code and data is taught a lot in Google Cloud Platform material, and the benefits are clear once done. In practice this means that the right tool for the right job when placing data somewhere, freeing up the code you write to run in more customised environments.
googleCloudRunner enables this workflow via the Cloud Build service. Cloud Build has been mentioned several times in tutorials of mine over the years, and has evolved from a handy online Docker builder service to a powerful continuous integration service, being able to sequence Dockerfiles on a shared workspace.
By separating out config and code I mean writing code that can quickly be applied to another project or client by replacing a config file, that points to the data locations and any other specific configurations for that project.
- Data - build steps via
gcloudor similar can import data from the appropriate GCP data service, such as DataStore or BigQuery - Code - Docker containers for each step means code is independent of the data you are working with
- Config - Cloud Build substitution macros configuration can be changed for new projects quickly.
All this encourages workflows that can be interchanged easily. For instance, to download Google Analytics data and upload to BigQuery could take this code/config for one client:
ga_to_bq <- cr_build_yaml(
steps = c(
cr_buildstep_decrypt(
id = "decrypt file",
cipher = "/workspace/auth.json.enc",
plain = "/workspace/auth.json",
keyring = "my-keyring",
key = "ga_auth"
),
cr_buildstep(
id = "download google analytics",
name = "gcr.io/gcer-public/gago:master",
env = c("GAGO_AUTH=/workspace/auth.json"),
args = c("reports",
"--view=$_VIEWID",
"--dims=ga:date,ga:medium",
"--mets=ga:sessions",
"--start=2014-01-01",
"--end=2019-11-30",
"--antisample",
"--max=-1",
"-o=google_analytics.csv"),
dir = "build"
),
cr_buildstep(
id = "load BigQuery",
name = "gcr.io/cloud-builders/gcloud",
entrypoint = "bq",
args = c("--location=EU",
"load",
"--autodetect",
"--source_format=CSV",
"$_BQTABLE",
"google_analytics.csv"
),
dir = "build"
)
),
substitutions = c(`_VIEWID` = 12345678, `_BQTABLE` = "test_EU.polygot")
)
# build the cloud build steps
build <- cr_build(ga_to_bq)
# schedule the build
cr_schedule("15 5 * * *", name="ga-to-bq-clienta",
httpTarget = cr_build_schedule_http(build))
The flexibility of the above when these elements are separated means:
- Data - the data is uploaded to BigQuery ready for use in other applications,
- Code - the code is separated within Docker containers so could be replaced (for instance swapping
gagofor agoogleAnalyticsRcontainer) - Config - for new clients swapping out the
$_VIEWIDand$_BQTABLEsubstitutions enables a quick turn-around.
Events not Schedules
Scheduling is a common use case for data pipelines, but it is not the ideal. Nothing is 100% reliable, so if a certain step fails then downstream schedules can all fail, which can involve some convoluted contingency code to deal with it. An example of this are the GA360 BigQuery exports, which although usually arrive before 0900 each day, but can sometimes be delayed by several hours. If they are, reports downstream can break.
Another example are database exports to Cloud Storage. CRM systems can delay, so a scheduled import from Cloud Storage may miss data.
Both the above scenarios can be solved if data flows are instead triggered via events rather than trusting a schedule. In GCP that means Cloud Pub/Sub, a message queue system that can be triggered from various events like BigQuery tables, GCP logs and Cloud Storage file updates.
Cloud Functions are a favourite of mine precisely because they can trigger off pub/sub messages, but up until recently this could only be utilised with Python, not R. (See this example for triggering transformations of GA360 BigQuery tables).
With Cloud Run, any code can run off HTTP events. googleCloudRunner includes helper functions that will use the plumber package to create an R API that can trigger off HTTP pub/sub events. From there, any R code can be triggered.
Creating the plumber API that supports pub/sub is carried out like below:
# example function echos back pubsub message
# change to do something more interesting with event data
pub <- function(x){
paste("Echo:", x)
}
#' Recieve pub/sub message
#' @post /pubsub
#' @param message a pub/sub message
function(message=NULL){
googleCloudRunner::cr_plumber_pubsub(message, pub)
}
A Dockerfile to run the plumber API like below:
FROM gcr.io/gcer-public/googlecloudrunner:master
COPY [".", "./"]
ENTRYPOINT ["R", "-e", "pr <- plumber::plumb(commandArgs()[4]); pr$run(host='0.0.0.0', port=as.numeric(Sys.getenv('PORT')))"]
CMD ["api.R"]
After which only one more function is needed to create an R API on Cloud Run:
cr_deploy_plumber("api_folder")
Any R code can now trigger when a Cloud Storage file is available or BigQuery table is filled, or any other Pub/Sub event. Reporting, anomaly detection, alerts, data updates are all good use cases.
Technical Debt of Code vs No-Code
One reason its been a while since my last R package is that any code created introduces a technical debt for its maintainers. Keeping up to date with dependency updates and bugs can suck up any time for new development. googleCloudRunner I believe will help move some of the use cases away from my other packages such as googleComputeEngineR.

Its obviously a lot easier to re-use someone’s code than create your own, and since googleCloudRunner’s integration with Cloud Build is Docker based, this means that the scope of which code to use within R is much increased. Any language’s application be be integrated with R via googleCloudRunner, so long as its in a Docker container.
A good example of this came up in the development of googleCloudRunner itself. I wanted to integrate with Cloud Run for the previous use case, but whilst using googleAuthR’s discovery API to generate code for simple functions like listing Cloud Run applications was fine, to deploy a Cloud Run service itself is non-trivial as it has lots of nested functionality involved such as integration with Anthos.
However, since I was already using Cloud Build to make the Docker container for eventual deployment to Cloud Run, why create a native R API wrapper when gcloud was available? And since Cloud Builds are running in the cloud, there is no issue with worrying about installing system depencies such as would be the case if calling python or gcloud natively on the R user’s system via system() commands.
And so it is that to deploy Cloud Run commands, the R function cr_run() triggers a Cloud Build calling gcloud run without you needing gcloud installed.
The docker based runsteps means you can use any pre-made Docker containers in other languages. For instance, the Slack buildstep below uses node.js. All this means that you can get up and running quickly with new functionality. A polygot example is included in the website documentation to highlight this flexibility. To round out this section, here is an example calling R to render an Rmd, Cloud Run to host it and Slack message when its done:
r <- "rmarkdown::render('scheduled_rmarkdown.Rmd', output_file = 'scheduled_rmarkdown.html')"
build_rmd <- cr_build_yaml(
steps = c(
cr_buildstep(
id = "download Rmd template",
name = "gsutil",
args = c("cp",
"gs://mark-edmondson-public-read/scheduled_rmarkdown.Rmd",
"scheduled_rmarkdown.Rmd"),
),
cr_buildstep_r(
id="render rmd",
r = r,
name = "gcr.io/gcer-public/render_rmd:master"
),
cr_buildstep_nginx_setup("/workspace/"),
cr_buildstep_docker("html-on-cloudrun", tag = "$BUILD_ID"),
cr_buildstep_run(name = "my-html-on-cloudrun",
image = "gcr.io/mark-edmondson-gde/html-on-cloudrun:$BUILD_ID",
concurrency = 80),
cr_buildstep_slack("deployed to Cloud Run")
),
images = "gcr.io/mark-edmondson-gde/html-on-cloudrun:$BUILD_ID",
)
An R philosophy is a Cloud philosophy?
I hope the above helps shows the ideas behind googleCloudRunner and how it can best help your own workflows. I finish now with an idea that perhaps its natural that R and the Cloud have been as focus of mine, since perhaps their philosophies overlap?
This obviously is not clear by the amount of R support in the cloud - first class support is usually reserved for more general purpose languages such as Python or Java. But as I was writing this I did notice some parallels:
- R favours a functional, interpreted language, rather than OO approach. This means no side effects such as f(x) -> x each time the function is invoked, whilst OO favour mutation of objects. Cloud micro-services are much easier when working in a stateless manner.
- Separation of code and data. As mentioned previously, cloud services encourage separation of code and data, and for reproducability R users have also been encouraged to do so.
- Vetting of R packages. R is one of the few languages where library dependencies are checked manually before being accepted into the central repository, CRAN. This helps keep a standard for security and patches.
- Side effect free functional functions can be asynchronously fired and suit patchy http connections.
Summary
I hope others will see the benefits I already am seeing from having googleCloudRunner in my data engineering armoury. There has already been good feedback from early users.
I’m also pleased that it has potential applications outside of R, since to my knowledge there are not yet other easy ways to generate cloudbuild.yml programatically, which is the backbone of the package. Looping creation of hundreds of Cloud Builds for distribution to other non-R using data workers, for instance, means one-off jobs and scripts can be safely banked for when needed or modified. It also makes it a lot easier to integrate R scripts into what non-R users are doing - killer features like the stat libraries, ggplot2, tidyverse, RMarkdown reports etc.
I wonder what the next meta-jump is from here and would be interested if you have some ideas. Multi-cloud? Multi-builds? I guess I’ll just have to wait to find out :)