
A new interest at the moment is engineering through various data privacy requirements with some of the new tools Google has available. With respect to my guiding principle of blogging about what I wish I could have read 6 months ago, I thought it worth writing about what is now possible. Data privacy engineering also requires clear thinking about the legal and technical details and so this will also help organise my communication around the subject.
It comes with great thanks to the #measure community that has helped discuss these topics, in particular the #data-protection-priv channel in Measure Slack in particular Aurelie Pols who has started a lot of the conversation about privacy within the industry, and a lot of the code snippets I’ve taken from Simo Ahava’s examples.
The usual disclaimers about this subject apply, that this is just free rantings so I’m not liable for anything I say here and you should seek your own legal advice.
Data Privacy is the new oil
Overall data privacy is becoming an increasingly hot topic, with it being talked about more and more within the general public. Whilst cookie banners have been around for at least 10 years, scandals like Cambridge Analytica have pushed data privacy to be an important issue, as scary futures are imagined where AI control our sub-conscious thoughts via our online activity data (cue Terminator/Skynet reference).
Whilst there are legitimate concerns, some of these reports are overblown and are just repeating hyperbole of ambitious marketing companies. However, public trust and how their personal data is being handled is more and more a business advantage.
There are also developing positions within the digital analytics community that I dub privacy hawks or doves.
 A privacy dove takes the position that all tracking is now forbidden if not explicitly agreed to and goes for a zero legal risk strategy, whilst a privacy hawk will allow tracking if its in the business interest, judging any legal risks to be less than the business gain.
A privacy dove takes the position that all tracking is now forbidden if not explicitly agreed to and goes for a zero legal risk strategy, whilst a privacy hawk will allow tracking if its in the business interest, judging any legal risks to be less than the business gain.

It obviously must be considered if that person’s salary depends on them being a privacy hawk or a privacy dove when taking advice. Most people I speak to are between the two extreme positions, generally supportive of not tracking individuals but not wanting to destroy all of their data via consent boxes to do so.
How much a company values data also factors. It follows that the more digitally mature a company is, the more valuable any lost data will be if they lose the ability to activate it, and the louder the privacy hawks arguments will be. As can be seen from some cookie consent implementations, privacy hawks value non-consented data enough to use dark patterns to try to collect more, such as pre-ticking boxes or using confusing UX to get users to opt-in.
Pre-ticked cookie consent
On the other hand, this also means that if a company has decided your data isn’t worth anything they may exclude you altogether - for example privacy doves judging that EU users on US websites are not worth any potential EU legal issues and so blocking all EU visitors.
The Legalese
For my digital analytics work, privacy engineering boils down to supporting three areas:
- ePrivacy - aka “the cookie law” about consent for tracking information on your computer
- ITP - Apple’s efforts to be the privacy alternative browser, and general browser driven privacy initiatives
- GDPR - Data privacy protection for people within the EU
The California Consumer Privacy Act (CCPA) is also relevant, but I will let Americans blog about that. There are also various other legislation around privacy being formulated around the world influenced by the above.
ePrivacy
The ePrivacy Directive is about accessing or recording data on your computer (or "terminal equipment"). It will eventually be replaced by the ePrivacy Regulation, the current draft of which allows exemptions for statistical uses, but it is not EU law yet. If it does get ratified then a lot of cookie consents may be unnecessary. Until then the text to rely on is Article 5(3).
From feedback I’ve got, ePrivacy compliance is the least clear as it changes from country to country and is currently under active review pending replacement, so interpretations of it are most varied. Cookie consent banners are now well established, but some privacy hawks consider work arounds like using localStorage instead of cookies valid, whilst privacy doves consider any information read or written in a persons browser is in need of a consent, including for example a browser’s user-agent.
ITP / Browser based data protections
ITP is the most rapidly changing in its reach and capabilities, but as its motivated by the richest company in the world’s market position (Apple) and not legislation, privacy hawks are more eager to circumnavigate around it, making it more like an arms race in measures and counter measures. ITP is a leader in the general trend of web browsers to respect privacy, with Firefox, Brave and even Chrome heading down the same path, and are arguably more powerful than governments in enforcing user privacy.
Apple’s moral authority in privacy is not helped whilst they are targets for complaints to do with violating the ePrivacy above, creating an advertisment ID (IDFA) for every iPhone on the planet with user consent.
Each iPhone runs on Apple’s iOS operating system. By default, iOS automatically generates a unique “IDFA” (short for Identifier for Advertisers) for each iPhone. Just like a license plate this unique string of numbers and characters allows Apple and other third parties to identify users across applications and even connect online and mobile behaviour (“cross device tracking”). Apple’s operating system creates the IDFA without user’s knowledge or consent. After its creation, Apple and third parties (e.g. applications providers and advertisers) can access the IDFA to track users’ behaviour, elaborate consumption preferences and provide personalised advertising. Such tracking is strictly regulated by the EU “Cookie Law” (Article 5(3) of the e-Privacy Directive) and requires the users’ informed and unambiguous consent.
GDPR
Feedback to me is that GDPR is usually the easiest to handle internally even if far reaching, since its well defined and fairly static in what it expects - you have to have issues such as being inflexible due to large scale or have IT problems to suffer from its consequences.

As I understand it, GDPR’s main purpose is for legal checks with the big internet companies such as Google, Facebook and Apple to protect EU citizens. The EU has horrors such as the holocaust to remember why protecting personal identity is important, vowing never again that personal identity can be used to discriminate against people. Remembering this is a useful principle when dealing with user privacy: leaking personal data is considered personal harm, and that harm has potential legal and ethical repercussions. It also features into privacy hawks calculus, since what the data is used for is important context: if you are using data to market medicine at children you will carry a much harsher penalty for wrong doing than if you use data to optimise your sales funnel.
GDPR and third parties like Google and Facebook
Where GDPR is a bit more hazy is how to treat the big data companies you may be partnering with.
The crux of the matter is usually whether these companies can be treated as Data Processors or Data Controllers. They will always argue the former, since that places the responsibility of personal data with you, the Data Controller. But if its ruled that these companies are using your data to identify individuals for their own purposes then they are Data Controllers, and need legal basis for that use.
For example, Google has been scrutinised for DoubleClick, since this has historically been identifying users across all of Google properties to offer back services such as display remarketing and look-a-like audiences, collecting data from all websites that take part in their network. This has turned into actual fines, being fined 50 million EUR last year by the French data regulator CNIL for not giving clear enough user consent. As the BBC reports:
CNIL said it had levied the record fine for “lack of transparency, inadequate information and lack of valid consent regarding ads personalisation”. The regulator said it judged that people were “not sufficiently informed” about how Google collected data to personalise advertising. “The information on processing operations for the ads personalisation is diluted in several documents and does not enable the user to be aware of their extent,” it said. It said the option to personalise ads was “pre-ticked” when creating an account, which did not respect the GDPR rules.
Privacy Shield

The latest chapter has been the potential loss of Privacy Shield in summer of 2020, which is a legal mechanism used to allow US companies to process EU data.
A key compliant from the records of the ruling was about how Facebook could be compelled to give EU citizen data to United States authorities such as the NSA or FBI, so violating that EU citizen’s GDPR protected rights:
In his reformulated complaint lodged on 1 December 2015, Mr Schrems claimed, inter alia, that United States law requires Facebook Inc. to make the personal data transferred to it available to certain United States authorities, such as the National Security Agency (NSA) and the Federal Bureau of Investigation (FBI). He submitted that, since that data was used in the context of various monitoring programmes in a manner incompatible with Articles 7, 8 and 47 of the Charter, the SCC Decision cannot justify the transfer of that data to the United States. In those circumstances, Mr Schrems asked the Commissioner to prohibit or suspend the transfer of his personal data to Facebook Inc.
With the loss of Privacy Shield, almost everyone using these companies in the EU will need to examine their data policies, since data is being sent to an untrusted country (the USA). This has prompted extreme reactions such as Facebook saying it will pull out from the EU. Pragmatically nothing is going to change just yet, whilst the EU sort out with those companies what happens next.
New privacy engineering tech from Google
We now have two new products in beta from the Google Tag Manager team - Google Consent Mode and Google Tag Manager - Server Side. Both allow a more nuanced approach to data collection for Google data products. With a combination of GTM-Server Side clients and Google Consent Mode, you can modify requests before the tags process it to help with your data privacy compliance. Some proof of concepts are below.
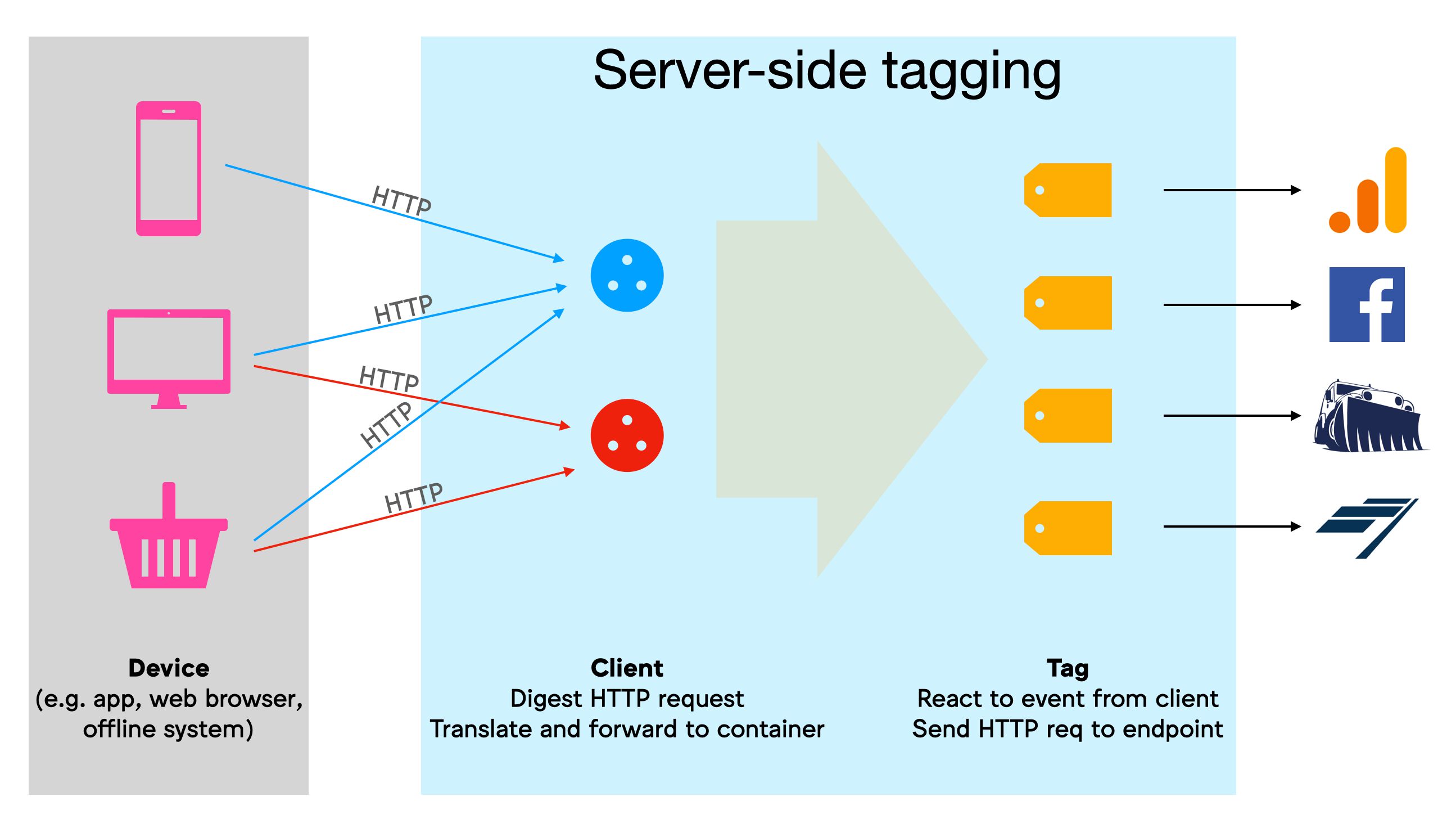
Image from Simo Ahava’s post - https://www.simoahava.com/analytics/server-side-tagging-google-tag-manager/
Since these products work with data before its sent, you can modify data to more exacting specifications to respect your approach to data privacy. This gives some new interesting engineering solutions for problems that may not have had easy answers before.
It also reverses a trend for Google Analytics in particular, which for years been working towards more integration with its services such as exporting segments for Google Ads or DoubleClick. Now the new privacy regulations have become business requirements, care needs to be done to reverse those integrations for opted-out users. Previously since Google Analytics data can be used for either statistics or marketing purposes, it meant an all-or-nothing approach to collecting data - opt-out: no data. With these new tools, more options are available.
GDPR Code examples
For GDPR, your main concern is to make sure that personal data is only collected with consent for it and its purpose, and that personal data is protected. There are different categories of data:
- personal information - also known as PII. Things that can be read to identify one person, such as emails, names, or addresses. It is best not to pass this unless absolutely necessary, as you will have to keep track of where it is stored so you can retrieve or delete it again later.
- pseudoanonymous - Use these instead if you can: its an ID that on its own gives no personal info, but once linked to other data can uniquely ID a user. UserIds, CookieIDs, IP addresses fall under here. GDPR encourages use of pseudoanonyminity as it means you can delete the personal data in one place, then destroy the psuedoanonymous keys to securely protect data, but you do need to protect that pseudoanonymous ID as you would personal data until that link is impossible.
- anonymous - Data that can not be used to identify (or re-identify) a user. This is useful as if you can make your data truly anonymous then GDPR does not apply. There is a great resource on what anonymisation you can do from the UK’s ICO that covers a lot of techniques.
Data Sanitisation of sensitive data
Data Sanitisation can also be performed. If there is a risk of personal information being accidentally passed into your systems, from say a search box where users accidental add their email (I’ve seen this due to bad website UX), rather than having to search through your data each time to delete it you can sanitise it before it even reaches Google Analytics. This code also runs on the server and not in the user’s browser, so offers speedups over other solutions out there using GTM customTasks.
The example below assumes your URLs could contain an email. I’m just looking for @ so this is a crude example, you may like this post by Brian Clifton for regex’s to tackle other privacy concerns to add more relevant ones for you.
const isRequestMpv1 = require('isRequestMpv1');
const extractEventsFromMpv1 = require('extractEventsFromMpv1');
const claimRequest = require('claimRequest');
// Check if request is Measurement Protocol
if (isRequestMpv1()) {
claimRequest();
const events = extractEventsFromMpv1();
events.forEach((event, i) => {
// if event is a page_view
if(event.event_name === "page_view"){
// we have suspected email address
if(event.page_location.contains("@")){
event.page_location = "[redacted]"
}
}
...etc...
});
}IP Anonymisation
IP addresses are explicitly mentioned in GDPR as personal identifiers. They are not recorded in Google Analytics but each request to Google’s servers do include one for spam and geo-location purposes - Google says this data is then quickly discarded. For some privacy doves this is not enough assurance, so instead you can roll your own ip anonymisation and geo targeting, never sending Google any ip information. (See here for setting an override in the GTM UI.)
Losing ip information also means losing geography dimensions, so see also this handy tip from Simo, which takes the geo-targeting info from the App Engine headers if you want to keep those, although then Google is receiving and processing an ip address.
Repeat for all fields you would like to control before Google sees them, such as User Agent.
...etc...
// Get IP from incoming request
const ip = getRemoteAddress();
// anonymise the ip address yourself
ips = ip.split(".")
anon_ip = ips[1]+"."+ips[2]+"."+ips[3]+".000"
// Check if request is Measurement Protocol
if (isRequestMpv1()) {
// Claim the request
claimRequest();
const events = extractEventsFromMpv1();
const max = events.length - 1;
events.forEach((event, i) => {
// Overwrite IP and UA with correct values
if (!event.ip_override && ip) event.ip_override = anon_ip;
//.. etc..
}
});Creating Psuedoanonymous identifiers
It may be you have some identifier for a user that you do not want to send to Google, or you want to perform psuedoanonymisation. Hashing algorithms are available in GTM server-side, meaning you can use those with a salt to create an ID that no-one at Google’s end could ever decode or link to other sources - much better to assure privacy doves that data could potentially be exposed or linked at Google’s end.
const claimRequest = require('claimRequest');
const getRemoteAddress = require('getRemoteAddress');
const getRequestHeader = require('getRequestHeader');
const sha256Sync = require('sha256Sync');
// Get User-Agent and IP from incoming request
const ua = getRequestHeader('user-agent');
const ip = getRemoteAddress();
// pick your own salt - can be anything
salt = 'dontknowwhattoputhere'
// Create a hashed ID from the IP and User Agent
const paid = sha256Sync(salt + ip + ua);
...etc...ePrivacy Code Examples
Google Consent Mode is a new product which integrates with services such as cookie consent banners to turn off cookies for both Google Analytics and Google Ads. Google Consent Mode offers a way to block cookies but preserve at least an anonymous hit for statistical use.
<script>
window.dataLayer = window.dataLayer || [];
function gtag() { dataLayer.push(arguments); }
// these should be changed upon user consent/denied
gtag('consent', 'default',
{ 'ad_storage': 'denied', 'analytics_storage': 'denied', 'wait_for_update': 500 });
gtag('set', 'url_passthrough', true);
</script>When Consent Mode is active and set to denied cookies, GA hits still occur and request a cookie but the responses do not include them. This means that every hit will generate a new cookieId (cid). Its just launched so more features are coming, but the hints are that Google will use machine learning to estimate sessions and goals with this data, without having personal data. See this guide from Simo on the nuts and bolts.
The requests also add a gcs=G100 parameter which when set means no data shows up in your Google Analytics account (aside the real-time reports). This may be ok for the privacy doves, at least those who don’t object to data still being seen by Google, but the more privacy hawkish may consider this non-consented, but anonymous data as value to also push to their own Google Analytics.
If you modify the gcs parameter, you can get the data into your GA account, but with the proviso that it will be 1 user, 1 session for each pageview as the cid is changing each time. For this reason you may want to send the data to a different view or property. Since we can change the measurementId in the request and don’t have cookies to worry about, you can modify that directly via the x-ga-measurement_id parameter.
This sets up separate data streams for your opt-in and opt-out users:
Thanks to Gunnar Griese, my colleague at IIH Nordic for help with the below
...etc...
if (isRequestMpv1()) {
// Claim the request
claimRequest();
const events = extractEventsFromMpv1();
const max = events.length - 1;
events.forEach((event, i) => {
// Make unconsented hits appear in GA
const consentMode = event['x-ga-gcs'];
if (consentMode == "G100") {
event['x-ga-gcs'] = "G111";
// change the measurementId to one for receiving opt-out users
event['x-ga-measurement_id'] = "UA-12345-3"
}
...etc...
})
}ITP Code Examples
ITP at the moment seems largely aimed at the cross-domain trackers that are building user profiles across many websites, such as display advertising networks. This means that measures are largely aimed at their techniques such as 3rd party cookies and CNAME cloaking, mostly by limiting cookie timeouts to 7 days. Privacy hawks can avoid being affected by those measures by using GTM Server Side to re-write cookies to HTTP (not affected by ITP).
The easiest method is to just activate the FPID in the default Google Analytics client in GTM, which migrates cookies over to HTTP. However, you may want to change the expiry period or have more control over these cookies, in which case see the script below taken from this post by Simo
const claimRequest = require('claimRequest');
const extractEventsFromMpv1 = require('extractEventsFromMpv1');
const getCookie = require('getCookieValues');
const getRemoteAddress = require('getRemoteAddress');
const getRequestHeader = require('getRequestHeader');
const isRequestMpv1 = require('isRequestMpv1');
const returnResponse = require('returnResponse');
const runContainer = require('runContainer');
const setCookie = require('setCookie');
const setPixelResponse = require('setPixelResponse');
const setResponseHeader = require('setResponseHeader');
// Get User-Agent and IP from incoming request
const ua = getRequestHeader('user-agent');
const ip = getRemoteAddress();
// Check if request is Measurement Protocol
if (isRequestMpv1()) {
// Claim the request
claimRequest();
const events = extractEventsFromMpv1();
const max = events.length - 1;
events.forEach((event, i) => {
// Unless the event had IP and user-agent overrides, manually
// override them with the IP and user-agent from the request
// That way the GA collect call will appear to have originated
// from the user's browser / device.
if(!event.ip_override && ip) event.ip_override = ip;
if(!event.user_agent && ua) event.user_agent = ua;
// Pass the event to a virtual container
runContainer(event, () => {
if (i === max) {
// Rewrite the _ga cookie to avoid Safari expiration.
const ga = getCookie('_ga');
if (ga && ga.length) {
setCookie('_ga', ga[0], {
domain: 'auto',
'max-age': 63072000,
path: '/',
secure: true,
sameSite: 'lax'
});
}
setPixelResponse();
// Make sure no CORS errors pop up with the response
const origin = getRequestHeader('Origin');
if (origin) {
setResponseHeader('Access-Control-Allow-Origin', origin);
setResponseHeader('Access-Control-Allow-Credentials', 'true');
}
returnResponse();
}
});
});
}As another browser based measure, you can also self-host your analytics script to avoid some Ad Blockers blocking your tracking scripts. Soon you will be able to host the Google Tag Manager script as well.
// analytics.js
if (getRequestPath() === '/analytics.js') {
claimRequest();
getGoogleScript('ANALYTICS', (script, metadata) => {
for (let header in metadata) {
setResponseHeader(header, metadata[header]);
}
const origin = getRequestHeader('Origin');
if (origin) {
setResponseHeader('Access-Control-Allow-Origin', origin);
setResponseHeader('Access-Control-Allow-Credentials', 'true');
}
setResponseHeader('content-type', 'text/javascript');
setResponseBody(script);
returnResponse();
});
}Summary
The best way to get good feedback on a subject is to confidently publish the wrong answer to the internet, so I hope that if I’ve made some glaring mistakes above someone will be kind enough to point it out in the comments below :) Its a big subject, this post is one of my longest, so I must have missed something.
Although a bit wary of the subject in the beginning I can see some exciting work in data privacy engineering, which lacks black and white certainties and so fosters interesting debates on ethics and how we want our digital society to look. As I know the value of my data from working in the industry, I am active in protecting my own personal data from being abused by companies on the web. I want other people to have that level of awareness and control and be able to make informed choices on what personal data they do give out.
There is also a big question mark on how improved data privacy will change the web, since a lot of the current legal targets look to be those companies that are driving revenue for news media, which in this age of alternative facts we have need of more than ever. It seems we also need to think about the business models to work alongside this improved privacy to make it all stick. Supporting publishers with subscriptions seems to be the way this is going, but for those to work even more data about subscribers will be needed by them to optimise their experience. Trust is a big factor in all of this, and if I was a brand I would be considering that a KPI to make long term gains.